Efficient scheduling of workflow actions in the cloud
My paper “Efficient Scheduling of Scientific Workflow Actions in the Cloud Based on Required Capabilities” has just been published in Springer’s Communications in Computer and Information Science book series (CCIS).
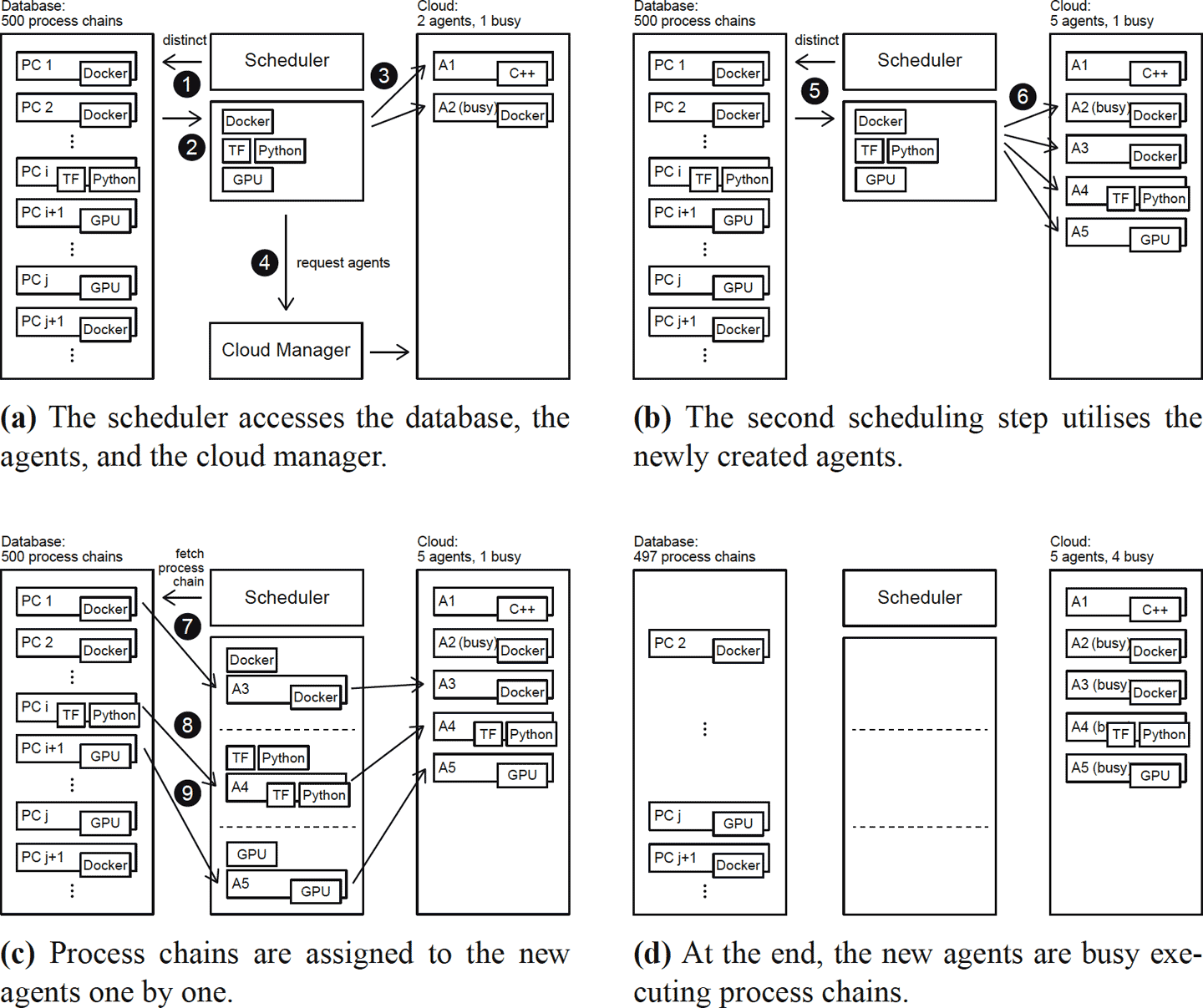
Distributed scientific workflow management systems processing large data sets in the Cloud face the following challenges: (a) workflow tasks require different capabilities from the machines on which they run, but at the same time, the infrastructure is highly heterogeneous, (b) the environment is dynamic and new resources can be added and removed at any time, (c) scientific workflows can become very large with hundreds of thousands of tasks, (d) faults can happen at any time in a distributed system.
In this paper, I present a software architecture and a capability-based scheduling algorithm that cover all these challenges in one design. My architecture consists of loosely coupled components that can run on separate virtual machines and communicate with each other over an event bus and through a database. The scheduling algorithm matches capabilities required by the tasks (e.g. software, CPU power, main memory, graphics processing unit) with those offered by the available virtual machines and assigns them accordingly for processing. My approach utilises heuristics to distribute the tasks evenly in the Cloud. This reduces the overall run time of workflows and makes efficient use of available resources. My scheduling algorithm also implements optimisations to achieve a high scalability. I perform a thorough evaluation based on four experiments and test if my approach meets the challenges mentioned above.
The paper finishes with a discussion, conclusions, and future research opportunities. An implementation of my algorithm and software architecture is publicly available with the open-source workflow management system Steep.
Reference

Download
According to Springer’s self-archiving policy, you may download the manuscript pre-print here. The final authenticated version is available on the publisher’s website.

Posted by Michel Krämer
on 23 July 2021
Next post
Enable GPU to speed up slow Playwright tests in headless mode
If you run your Playwright tests in headless mode, chances are your browser uses a slow software renderer. This post explains how you can speed up your tests by enabling hardware acceleration.
Previous post
Steep 5.8.0
I’m thrilled to announce the new version of the scientific workflow management system Steep. This release contains many features including the possibility to resume process chains after a scheduler instance has crashed.
Related posts
Two new cloud-based data processing papers published
My latest research papers about “Capability-based Scheduling of Scientific Workflows in the Cloud” and “Scalable processing of massive geodata in the cloud” are now available.
Steep - Run Scientific Workflows in the Cloud
I’m thrilled to announce that the workflow management system I’ve been working on for the last couple of years is now open-source! Read more about Steep and its features in this blog post.
Executing cyclic scientific workflows in the cloud
Our paper has just been published in the journal of cloud computing. We present an approach for a cloud-based system executing scientific workflows whose structure may change during run time.