Two new cloud-based data processing papers published
Two of my latest research papers about cloud-based data processing have just been published. The first paper is entitled “Capability-based Scheduling of Scientific Workflows in the Cloud” and deals with the scheduling algorithm I implemented in Steep. I presented this paper at the 9th International Conference on Data Science, Technology and Applications (DATA), which was held as a virtual conference due to COVID-19.
The other paper entitled “Scalable processing of massive geodata in the cloud: generating a level-of-detail structure optimized for web visualization” was a joint collaboration with Ralf Gutbell, Hendrik M. Würz, and Jannis Weil where we implemented an approach to distributed triangulation of digital terrain models with Apache Spark and GeoTrellis. This journal article has been published in the AGILE GIScience Series.
Please find details about the papers, the conference presentation of the first one, as well as the full references below.
Capability-based Scheduling of Scientific Workflows in the Cloud
In this paper, I presented a distributed task scheduling algorithm and a software architecture for a system executing scientific workflows in the Cloud. The main challenges I addressed are (i) capability-based scheduling, which means that individual workflow tasks may require specific capabilities from highly heterogeneous compute machines in the Cloud, (ii) a dynamic environment where resources can be added and removed on demand, (iii) scalability in terms of scientific workflows consisting of hundreds of thousands of tasks, and (iv) fault tolerance because in the Cloud, faults can happen at any time.

My software architecture consists of loosely coupled components communicating with each other through an event bus and a shared database. Workflow graphs are converted to process chains that can be scheduled independently.

My scheduling algorithm collects distinct required capability sets for the process chains, asks the agents which of these sets they can manage, and then assigns process chains accordingly.
I presented the results of four experiments I conducted to evaluate if my approach meets the aforementioned challenges. The paper finishes with a discussion, conclusions, and future research opportunities.
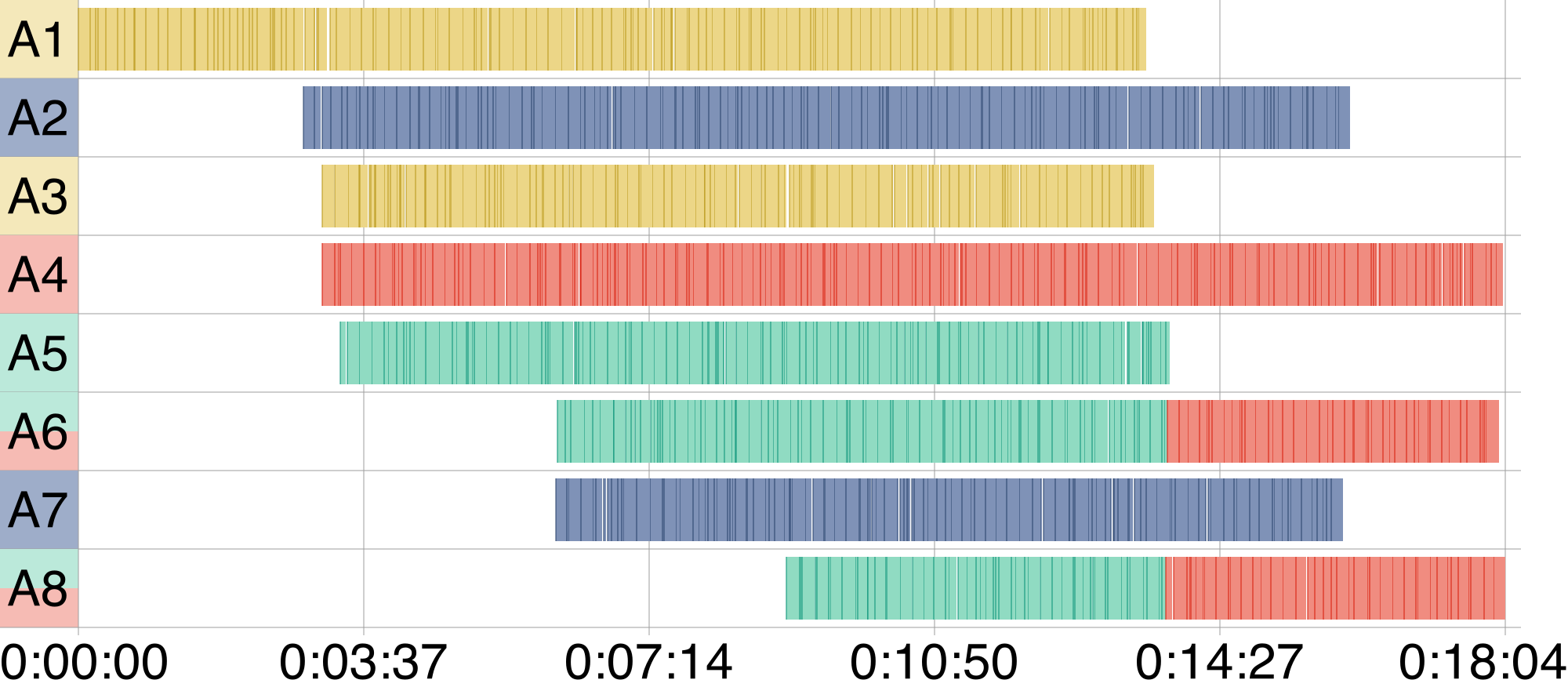
An implementation of my algorithm and software architecture is publicly available with the open-source workflow management system Steep.
Presentation
Here are the slides of the presentation I gave at the DATA conference:
Reference

Download
The paper has been published under the CC BY-NC-ND 4.0 license. You may download the final manuscript here.
Scalable processing of massive geodata in the cloud
In this paper, we described a cloud-based approach to transform arbitrarily large terrain data to a hierarchical level-of-detail structure that is optimized for web visualization. Our approach is based on a divide-and-conquer strategy. The input data is split into tiles that are distributed to individual workers in the cloud. These workers apply a Delaunay triangulation with a maximum number of points and a maximum geometric error. They merge the results and triangulate them again to generate less detailed tiles. The process repeats until a hierarchical tree of different levels of detail has been created. This tree can be used to stream the data to the web browser.
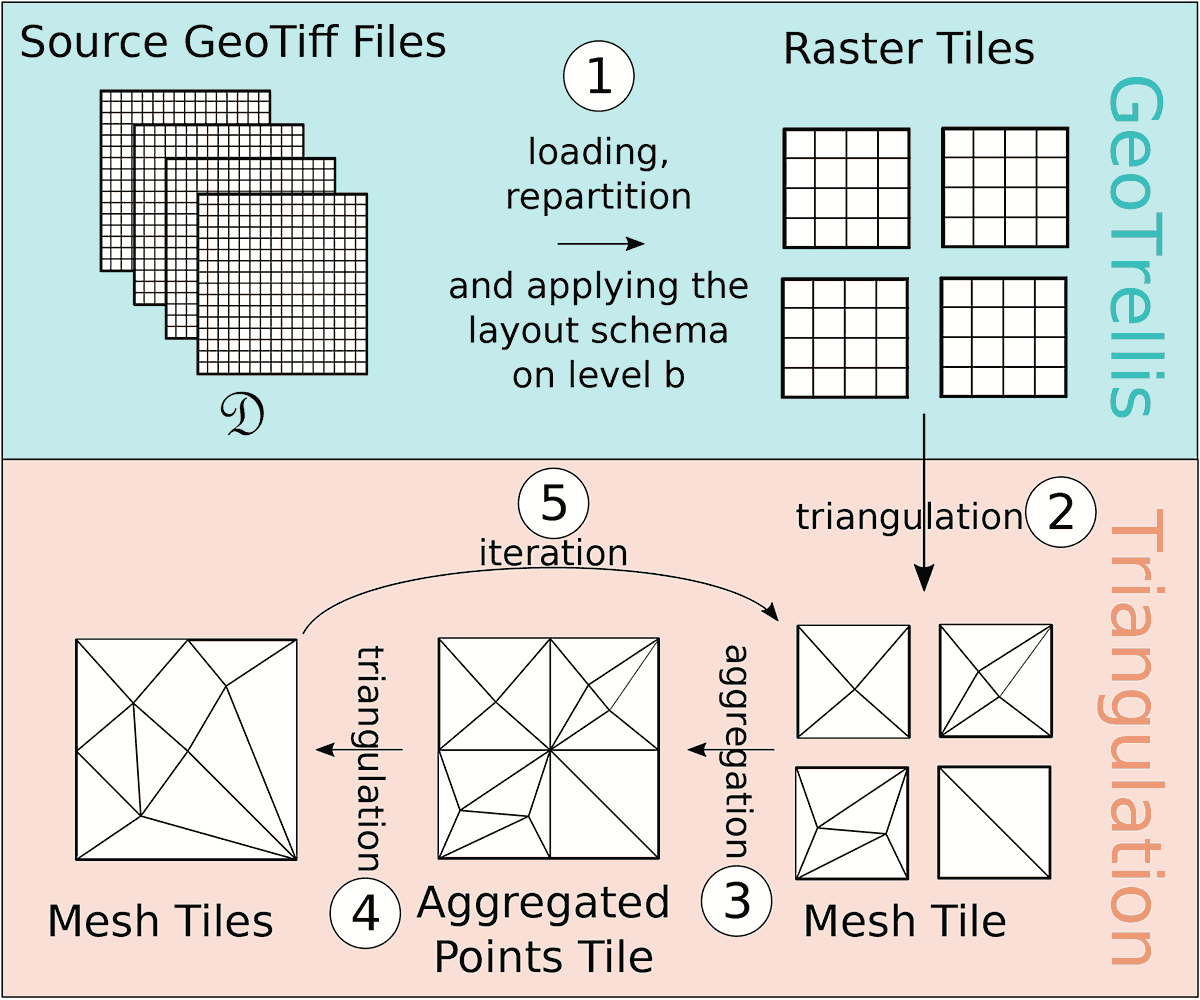
We have implemented this approach in the frameworks Apache Spark and GeoTrellis. Our paper includes an evaluation of our approach and the implementation. We focus on scalability and runtime but also investigate bottlenecks, possible reasons for them, as well as options for mitigation. The results of our evaluation show that our approach and implementation are scalable and that we are able to process massive terrain data.
Reference

Download
The paper has been published under the CC-BY 4.0 license. You may download the final manuscript here.

Posted by Michel Krämer
on 16 July 2020
Next post
Steep 5.3.0 has been released
A new minor version has been released. It deprecates a few properties in the workflow and process chain models and offers a few other features such as separate SSH usernames per setup and a new workflow validator.
Previous post
Steep 5.1.0 has just been released
The new version of my scientific workflow management system Steep introduces a reworked and modern web-based user interface. It also provides new features that make work with workflows and process chains easier.
Related posts
Steep - Run Scientific Workflows in the Cloud
I’m thrilled to announce that the workflow management system I’ve been working on for the last couple of years is now open-source! Read more about Steep and its features in this blog post.
Steep 5.6.0
The new version of my scientific workflow management system highlights automatic retrying of individual services, multiple agents per Steep instance, an optimised scheduling algorithm, and many other new features.
Efficient scheduling of workflow actions in the cloud
My latest paper about scheduling workflow actions based on required capabilities has just been published Springer’s Communications in Computer and Information Science book series.